位运算实用教程
首先声明这个文章不是我原创,功劳归 Matrix67(First Published By Matrix67)但合并,整理 + 改编后效果更好,也删除和添加了一些东西,献给所有需要的人。首先还是从最基础的东西说起。
什么是位运算?
程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算说穿了,就是直接对整数在内存中的二进制位进行操作。
比如,and运算本来是一个逻辑运算 符,但整数与整数之间也可以进行and运算。举个例子,6的二进制是110,11的二进制是1011,那么6 and 11的结果就是2,它是二进制对应位进行逻辑运算的结果(0表示False,1表示True,空位都当0处理):
110
AND 1011
0010 –> 2
由于位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
当然有人会说,这个快了有什么用,计算6 and 11没有什么实际意义啊。这一系列的文章就将告诉你,位运算到底可以干什么,有些什么经典应用,以及如何用位运算优化你的程序。
Pascal和C中的位运算符号
下面的a和b都是整数类型,则:
| C语言 | Pascal语言 |
|---|---|
| a & b | a and b |
| a | b |
| a ^ b | a xor b |
| ~a | not a |
| a « b | a shl b |
| a » b | a shr b |
注意C中的逻辑运算和位运算符号是不同的。520|1314=1834,但520||1314=1,因为逻辑运算时520和1314都相当于True。同样的,!a和~a也是有区别的。
各种位运算的使用
and运算
and运算通常用于二进制取位操作,例如一个数 and 1的结果就是取二进制的最末位。这可以用来判断一个整数的奇偶,二进制的最末位为0表示该数为偶数,最末位为1表示该数为奇数.
or运算
or运算通常用于二进制特定位上的无条件赋值,例如一个数or 1的结果就是把二进制最末位强行变成1。如果需要把二进制最末位变成0,对这个数or 1之后再减一就可以了,其实际意义就是把这个数强行变成最接近的偶数。
xor运算
xor运算通常用于对二进制的特定一位进行取反操作,因为异或可以这样定义:0和1异或0都不变,异或1则取反。 xor 运算的逆运算是它本身,也就是说两次异或同一个数最后结果不变,即(a xor b) xor b = a。xor运算可以用于简单的加密,比如我想对我MM说1314520,但怕别人知道,于是双方约定拿我的生日19880516作为密钥。1314520 xor 19880516 = 20665500,我就把20665500告诉MM。MM再次计算20665500 xor 19880516的值,得到1314520,于是她就明白了我的企图。
下面我们看另外一个东西。定义两个符号#和@(我怎么找不到那个圈里有个叉的字符),这两个符号互为逆运算,也就是说(x # y) @ y = x。
现在依次执行下面三条命令,结果是什么? x <- x # y y <- x @ y x <- x @ y
执行了第一句后x变成了x # y。那么第二句实质就是y <- x # y @ y,由于#和@互为逆运算,那么此时的y变成了原来的x。
第三句中x实际上被赋值为(x # y) @ x,如果#运算具有交换律,那么赋值后x就变成最初的y了。这三句话的结果是,x和y的位置互换了。 加法和减法互为逆运算,并且加法满足交换律。把#换成+,把@换成-,我们可以写出一个不需要临时变量的swap过程(Pascal)。
procedure swap(var a,b:longint);
begin
a:=a + b;
b:=a - b;
a:=a - b;
end;
not运算
not 运算的定义是把内存中的0和1全部取反。使用not运算时要格外小心,你需要注意整数类型有没有符号。如果not的对象是无符号整数(不能表示负数),那 么得到的值就是它与该类型上界的差,因为无符号类型的数是用$0000到$FFFF依次表示的。
下面的两个程序(仅语言不同)均返回65435。
var a:word;
begin
a:=100;
a:=not a;
writeln(a);
end
#include <stdio.h>
int main() {
unsigned short a=100;
a = ~a;
printf( "%d\n", a );
return 0;
}
如果not的对象是有符号的整数,情况就不一样了,稍后我们会在「整数类型的储存」小节中提到。
shl运算
a shl b就表示把a转为二进制后左移b位(在后面添b个0)。例如100的二进制为1100100,而110010000转成十进制是400,那么100 shl 2 = 400。可以看出,a shl b的值实际上就是a乘以2的b次方,因为在二进制数后添一个0就相当于该数乘以2。 通常认为a shl 1比a * 2更快,因为前者是更底层一些的操作。因此程序中乘以2的操作请尽量用左移一位来代替。
定义一些常量可能会用到shl运算。你可以方便地用1 shl 16 - 1来表示65535。
很多算法和数据结构要求数据规模必须是2的幂,此时可以用shl来定义Max_N等常量。
shr运算
和 shl相似,a shr b表示二进制右移b位(去掉末b位),相当于a除以2的b次方(取整)。我们也经常用shr 1来代替div 2,比如二分查找、堆的插入操作等等。想办法用shr代替除法运算可以使程序效率大大提高。最大公约数的二进制算法用除以2操作来代替慢得出奇的mod运 算,效率可以提高60%。
位运算的简单应用
有时我们的程序需要一个规模不大的Hash表来记录状态。比如,做数独时我们需要27个Hash表来统计每一行、每一列和每一个小九宫格里已经有哪些数了。此时,我们可以用27个小于 2^9 的整数进行记录。例如,一个只填了2和5的小九宫格就用数字18表示(二进制为000010010),而某一行的状态为511则表示这一行已经填 满。需要改变状态时我们不需要把这个数转成二进制修改后再转回去,而是直接进行位操作。在搜索时,把状态表示成整数可以更好地进行判重等操作。这是在搜索 中使用位运算加速的经典例子。以后我们会看到更多的例子。 下面列举了一些常见的二进制位的变换操作。
| 功能 | 示例 | 位运算 |
|---|---|---|
| 去掉最后一位 | (101101->10110) | x shr 1 |
| 在最后加一个0 | (101101->1011010) | x shl 1 |
| 在最后加一个1 | (101101->1011011) | x shl 1+1 |
| 把最后一位变成1 | (101100->101101) | x or 1 |
| 把最后一位变成0 | (101101->101100) | x or 1-1 |
| 最后一位取反 | (101101->101100) | x xor 1 |
| 把右数第k位变成1 | (101001->101101,k=3) | x or (1 shl (k-1)) |
| 把右数第k位变成0 | (101101->101001,k=3) | x and not (1 shl (k-1)) |
| 右数第k位取反 | (101001->101101,k=3) | x xor (1 shl (k-1)) |
| 取末三位 | (1101101->101) | x and 7 |
| 取末k位 | (1101101->1101,k=5) | x and (1 shl k-1) |
| 取右数第k位 | (1101101->1,k=4) | x shr (k-1) and 1 |
| 把末k位变成1 | (101001->101111,k=4) | x or (1 shl k-1) |
| 末k位取反 | (101001->100110,k=4) | x xor (1 shl k-1) |
| 把右边连续的1变成0 | (100101111->100100000) | x and (x+1) |
| 把右起第一个0变成1 | (100101111->100111111) | x or (x+1) |
| 把右边连续的0变成1 | (11011000->11011111) | x or (x-1) |
| 取右边连续的1 | (100101111->1111) | (x xor (x+1)) shr 1 |
| 去掉右起第一个1的左边 | (100101000->1000) | x and (x xor (x-1)) |
最后这一个在树状数组中会用到。
Pascal和C中的16进制表示
Pascal中需要在16进制数前加$符号表示,C中需要在前面加0x来表示。这个以后我们会经常用到。
整数类型的储存
我们前面所说的位运算都没有涉及负数,都假设这些运算是在 unsigned/word 类型(只能表示正数的整型)上进行操作。但计算机如何处理有正负符号的整数类型呢?下面两个程序都是考察 16 位整数的储存方式(只是语言不同)。
var a, b: integer;
begin
a := $0000;
b := $0001;
write(a, ' ', b, ' ');
a := $FFFE;
b := $FFFF;
write(a, ' ', b, ' ');
a := $7FFF;
b := $8000;
writeln(a, ' ', b);
end.
#include <stdio.h>
int main() {
short int a, b;
a = 0x0000;
b = 0x0001;
printf("%d %d ", a, b);
a = 0xFFFE;
b = 0xFFFF;
printf("%d %d ", a, b);
a = 0x7FFF;
b = 0x8000;
printf("%d %d\n", a, b);
return 0;
}
两个程序的输出均为 0 1 -2 -1 32767 -32768。其中前两个数是内存值最小的时候,中间两个数则是内存值最大的时候,最后输出的两个数是正数与负数的分界处。由此你可以清楚地看到计算机是如何储存一个整数的:计算机用 $0000 到 $7FFF 依次表示 0 到 32767 的数,剩下的 $8000 到 $FFFF 依次表示 -32768 到 -1 的数。32 位有符号整数的储存方式也是类似的。
稍加注意你会发现,二进制的第一位是用来表示正负号的,0 表示正,1 表示负。这里有一个问题:0 本来既不是正数,也不是负数,但它占用了 $0000 的位置,因此有符号的整数类型范围中正数个数比负数少一个。对一个有符号的数进行 not 运算后,最高位的变化将导致正负颠倒,并且数的绝对值会差 1。也就是说,not a 实际上等于 -a-1。这种整数储存方式叫做「补码」。
二进制中的1有奇数个还是偶数个
我们可以用下面的代码来计算一个32位整数的二进制中1的个数的奇偶性,当输入数据的二进制表示里有偶数个数字1时程序输出0,有奇数个则输出1。例如,1314520的二进制101000000111011011000中有9个1,则x=1314520时程序输出1。
var i,x,c:longint;
begin
readln(x);
c:=0;
for i:=1 to 32 do
begin
c:=c + x and 1;
x:=x shr 1;
end;
writeln( c and 1 );
end.
但这样的效率并不高,位运算的神奇之处还没有体现出来。同样是判断二进制中1的个数的奇偶性,下面这段代码就强了。你能看出这个代码的原理吗?
var x:longint;
begin
readln(x);
x:=x xor (x shr 1);
x:=x xor (x shr 2);
x:=x xor (x shr 4);
x:=x xor (x shr 8);
x:=x xor (x shr 16);
writeln(x and 1);
end.
为了说明上面这段代码的原理,我们还是拿1314520出来说事。1314520的二进制为101000000111011011000,第一次异或操作的结果如下:
00000000000101000000111011011000 XOR 0000000000010100000011101101100
---------------------------------------
00000000000111100000100110110100
得到的结果是一个新的二进制数,其中右起第i位上的数表示原数中第i和i+1位上有奇数个1还是偶数个1。比如,最右边那个0表示原数末两位有偶数个1,右起第3位上的1就表示原数的这个位置和前一个位置中有奇数个1。对这个数进行第二次异或的结果如下:
00000000000111100000100110110100 XOR 000000000001111000001001101101
---------------------------------------
00000000000110011000101111011001
结果里的每个1表示原数的该位置及其前面三个位置中共有奇数个1,每个0就表示原数对应的四个位置上共偶数个1。一直做到第五次异或结束后,得到的二进制数的最末位就表示整个32位数里有多少个1,这就是我们最终想要的答案。
计算二进制中的1的个数
同样假设x是一个32位整数。经过下面五次赋值后,x的值就是原数的二进制表示中数字1的个数。比如,初始时x为1314520,那么最后x就变成了9,它表示1314520的二进制中有9个1。
x := (x and $55555555) + ((x shr 1) and $55555555);
x := (x and $33333333) + ((x shr 2) and $33333333);
x := (x and $0F0F0F0F) + ((x shr 4) and $0F0F0F0F);
x := (x and $00FF00FF) + ((x shr 8) and $00FF00FF);
x := (x and $0000FFFF) + ((x shr 16) and $0000FFFF);
为了便于解说,我们下面仅说明这个程序是如何对一个8位整数进行处理的。我们拿数字211来开刀。211的二进制为11010011。
+---+---+---+---+---+---+---+---+
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | <---原数
+---+---+---+---+---+---+---+---+
| 1 0 | 0 1 | 0 0 | 1 0 | <---第一次运算后
+-------+-------+-------+-------+
| 0 0 1 1 | 0 0 1 0 | <---第二次运算后
+---------------+---------------+
| 0 0 0 0 0 1 0 1 | <---第三次运算后,得数为5
+-------------------------------+
整个程序是一个分治的思想。第一次我们把每相邻的两位加起来,得到每两位里1的个数,比如前两位10就表示原数的前两位有2个1。第二次我们继续两两相加,10+01=11,00+10=10,得到的结果是00110010,它表示原数前4位有3个1,末4位有2个1。最后一次我们把0011和0010加起来,得到的就是整个二进制中1的个数。程序中巧妙地使用取位和右移,比如第二行中$33333333的二进制为00110011001100….,用它和x做and运算就相当于以2为单位间隔取数。shr的作用就是让加法运算的相同数位对齐。
二分查找32位整数的前导0个数
这里用的C语言,我直接Copy的Hacker’s Delight上的代码。这段代码写成C要好看些,写成Pascal的话会出现很多begin和end,搞得代码很难看。程序思想是二分查找,应该很简单,我就不细说了。
int nlz(unsigned x) {
int n;
if (x == 0) return(32);
n = 1;
if ((x >> 16) == 0) {n = n +16; x = x <<16;}
if ((x >> 24) == 0) {n = n + 8; x = x << 8;}
if ((x >> 28) == 0) {n = n + 4; x = x << 4;}
if ((x >> 30) == 0) {n = n + 2; x = x << 2;}
n = n - (x >> 31);
return n;
}
只用位运算来取绝对值
这是一个非常有趣的问题。大家先自己想想吧。
答案:假设x为32位整数,则x xor (not (x shr 31) + 1) + x shr 31的结果是x的绝对值 x shr 31是二进制的最高位,它用来表示x的符号。如果它为0(x为正),则not (x shr 31) + 1等于$00000000,异或任何数结果都不变;如果最高位为1(x为负),则not (x shr 31) + 1等于$FFFFFFFF,x异或它相当于所有数位取反,异或完后再加一。
高低位交换
题目是这样:
给出一个小于2^32的正整数。这个数可以用一个32位的二进制数表示(不足32位用0补足)。我们称这个二进制数的前16位为「高位」,后16位为「低位」。将它的高低位交换,我们可以得到一个新的数。试问这个新的数是多少(用十进制表示)。
例如,数1314520用二进制表示为0000 0000 0001 0100 0000 1110 1101 1000(添加了11个前导0补足为32位),其中前16位为高位,即0000 0000 0001 0100;后16位为低位,即0000 1110 1101 1000。将它的高低位进行交换,我们得到了一个新的二进制数0000 1110 1101 1000 0000 0000 0001 0100。它即是十进制的249036820。
当时几乎没有人想到用一句位操作来代替冗长的程序。使用位运算的话两句话就完了。
var n:dword;
begin
readln( n );
writeln( (n shr 16) or (n shl 16) );
end.
而事实上,Pascal有一个系统函数swap直接就可以用。
二进制逆序
下面的程序读入一个32位整数并输出它的二进制倒序后所表示的数。
输入: 1314520 (二进制为00000000000101000000111011011000) 输出: 460335104 (二进制为00011011011100000010100000000000)
var x:dword;
begin
readln(x);
x := (x and $55555555) shl 1 or (x and $AAAAAAAA) shr 1;
x := (x and $33333333) shl 2 or (x and $CCCCCCCC) shr 2;
x := (x and $0F0F0F0F) shl 4 or (x and $F0F0F0F0) shr 4;
x := (x and $00FF00FF) shl 8 or (x and $FF00FF00) shr 8;
x := (x and $0000FFFF) shl 16 or (x and $FFFF0000) shr 16;
writeln(x);
end.
它的原理和刚才求二进制中1的个数那个例题是大致相同的。程序首先交换每相邻两位上的数,以后把互相交换过的数看成一个整体,继续进行以2位为单位、以4位为单位的左右对换操作。我们再次用8位整数211来演示程序执行过程:
+---+---+---+---+---+---+---+---+
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | <---原数
+---+---+---+---+---+---+---+---+
| 1 1 | 1 0 | 0 0 | 1 1 | <---第一次运算后
+-------+-------+-------+-------+
| 1 0 1 1 | 1 1 0 0 | <---第二次运算后
+---------------+---------------+
| 1 1 0 0 1 0 1 1 | <---第三次运算后
+-------------------------------+
n皇后问题位运算版
n 皇后问题是啥我就不说了吧,学编程的肯定都见过。下面的十多行代码是n皇后问题的一个高效位运算程序,看到过的人都夸它牛。初始时,upperlim:= (1 shl n)-1。主程序调用test(0,0,0)后sum的值就是n皇后总的解数。拿这个去交USACO,0.3s。
procedure test(row,ld,rd:longint);
var pos,p:longint;
begin
if row<>upperlim then
begin
pos:=upperlim and not (row or ld or rd);
while pos<>0 do
begin
p:=pos and -pos;
pos:=pos-p;
test(row+p,(ld+p)shl 1,(rd+p)shr 1);
end;
end
else inc(sum);
end;
乍一看似乎完全摸不着头脑,实际上整个程序是非常容易理解的。这里还是建议大家自己单步运行一探究竟,实在没研究出来再看下面的解说。
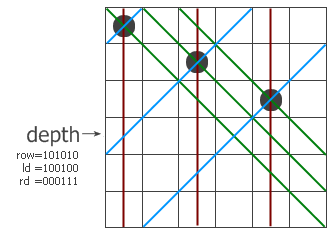
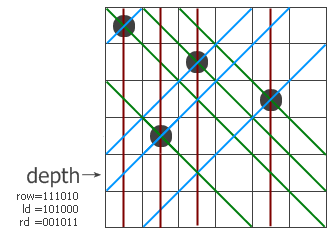
和普通算法一样,这是一个递归过程,程序一行一行地寻找可以放皇后的地方。过程带三个参数,row、ld和rd,分别表示在纵列和两个对角线方向的限制条件 下这一行的哪些地方不能放。我们以6x6的棋盘为例,看看程序是怎么工作的。假设现在已经递归到第四层,前三层放的子已经标在左图上了。红色、蓝色和绿色 的线分别表示三个方向上有冲突的位置,位于该行上的冲突位置就用row、ld和rd中的1来表示。把它们三个并起来,得到该行所有的禁位,取反后就得到所 有可以放的位置(用pos来表示)。前面说过-a相当于not a + 1,这里的代码第6行就相当于pos and (not pos + 1),其结果是取出最右边的那个1。这样,p就表示该行的某个可以放子的位置,把它从pos中移除并递归调用test过程。注意递归调用时三个参数的变 化,每个参数都加上了一个禁位,但两个对角线方向的禁位对下一行的影响需要平移一位。最后,如果递归到某个时候发现row=111111了,说明六个皇后 全放进去了,此时程序从第1行跳到第11行,找到的解的个数加一。
Gray码
假如我有4个潜在的GF,我需要决定最终到底和谁在一起。一个简单的办法就是,依次和每个MM交往一段时间,最后选择给我带来的「满意度」最大的MM。但看了dd牛的理论后,事情开始变得复杂了:我可以选择和多个MM在一起。这样,需要考核的状态变成了2^4=16种(当然包括0000这一状态,因为我有可能是玻璃)。
现在的问题就是,我应该用什么顺序来遍历这16种状态呢?传统的做法是,用二进制数的顺序来遍历所有可能的组合。也就是说,我需要以 0000->0001->0010->0011->0100->…->1111这样的顺序对每种状态进行测试。
这个顺序很不科学,很多时候状态的转移都很耗时。比如从0111到1000时我需要暂时甩掉当前所有的3个MM,然后去把第4个MM。同时改变所有MM与我的关系是一件何等巨大的工程啊。因此,我希望知道,是否有一种方法可以使得,从没有MM这一状态出发,每次只改变我和一个MM的关系(追或者甩),15次操作后恰好遍历完所有可能的组合(最终状态不一定是1111)。大家自己先试一试看行不行。
解决这个问题的方法很巧妙。我们来说明,假如我们已经知道了n=2时的合法遍历顺序,我们如何得到n=3的遍历顺序。显然,n=2的遍历顺序如下:
00 01 11 10
你可能已经想到了如何把上面的遍历顺序扩展到n=3的情况。n=3时一共有8种状态,其中前面4个把n=2的遍历顺序照搬下来,然后把它们对称翻折下去并在最前面加上1作为后面4个状态:
000 001 011 010 ↑ ——– 110 ↓ 111 101 100
用这种方法得到的遍历顺序显然符合要求。首先,上面8个状态恰好是n=3时的所有8种组合,因为它们是在n=2的全部四种组合的基础上考虑选不选第3个元素所得到的。然后我们看到,后面一半的状态应该和前面一半一样满足「相邻状态间仅一位不同」的限制,而「镜面」处则是最前面那一位数不同。再次翻折三阶遍历顺序,我们就得到了刚才的问题的答案:
0000 0001 0011 0010 0110 0111 0101 0100 1100 1101 1111 1110 1010 1011 1001 1000
这种遍历顺序作为一种编码方式存在,叫做Gray码(写个中文让蜘蛛来抓:格雷码)。它的应用范围很广。比如,n阶的Gray码相当于在n维立方体上的Hamilton回路,因为沿着立方体上的边走一步,n维坐标中只会有一个值改变。再比如,Gray码和Hanoi塔问题等价。Gray码改变的是第几个数,Hanoi塔就该移动哪个盘子。比如,3阶的Gray码每次改变的元素所在位置依次为1-2-1-3-1-2-1,这正好是3阶Hanoi塔每次移动盘子编号。如果我们可以快速求出Gray码的第n个数是多少,我们就可以输出任意步数后Hanoi塔的移动步骤。现在我告诉你,Gray码的第n个数(从0算起)是n xor (n shr 1),你能想出来这是为什么吗?先自己想想吧。
下面我们把二进制数和Gray码都写在下面,可以看到左边的数异或自身右移的结果就等于右边的数。
| 二进制数 | Gray码 |
|---|---|
| 000 | 000 |
| 001 | 001 |
| 010 | 011 |
| 011 | 010 |
| 100 | 110 |
| 101 | 111 |
| 110 | 101 |
| 111 | 100 |
从二进制数的角度看,「镜像」位置上的数即是对原数进行not运算后的结果。比如,第3个数010和倒数第3个数101的每一位都正好相反。假设这两个数分别为x和y,那么x xor (x shr 1)和y xor (y shr 1)的结果只有一点不同:后者的首位是1,前者的首位是0。而这正好是Gray码的生成方法。这就说明了,Gray码的第n个数确实是n xor (n shr 1)。
这个题目,是二维意义上的Gray码。题目大意是说,把0到2^(n+m)-1的数写成2^n * 2^m的矩阵,使得位置相邻两数的二进制表示只有一位之差。答案其实很简单,所有数都是由m位的Gray码和n位Gray码拼接而成,需要用左移操作和or运算完成。完整的代码如下:
var x,y,m,n,u:longint;
begin
readln(m,n);
for x:=0 to 1 shl m-1 do
begin
u:=(x xor (x shr 1)) shl n; //输出数的左边是一个m位的Gray码
for y:=0 to 1 shl n-1 do
write(u or (y xor (y shr 1)),' '); //并上一个n位Gray码
writeln;
end;
end.
下面分享的是Matrix67写的三个代码,里面有些题目也是Matrix67自己出的。这些代码都是在Matrix67的Pascal时代写的,恕不提供C语言了。代码写得并不好,我只是想告诉大家位运算在实战中的应用,包括了搜索和状态压缩DP方面的题目。其实大家可以在网上找到更多用位运算优化的题目,这里整理出一些Matrix67写的代码。
Problem : 费解的开关
06年NOIp模拟赛(一) by Matrix67 第四题
问题描述
你玩过「拉灯」游戏吗?25盏灯排成一个5x5的方形。每一个灯都有一个开关,游戏者可以改变它的状态。每一步,游戏者可以改变某一个灯的状态。游戏者改变一个灯的状态会产生连锁反应:和这个灯上下左右相邻的灯也要相应地改变其状态。 我们用数字「1」表示一盏开着的灯,用数字「0」表示关着的灯。下面这种状态
10111 01101 10111 10000 11011
在改变了最左上角的灯的状态后将变成:
01111 11101 10111 10000 11011
再改变它正中间的灯后状态将变成:
01111 11001 11001 10100 11011
给定一些游戏的初始状态,编写程序判断游戏者是否可能在6步以内使所有的灯都变亮。
输入格式 第一行有一个正整数n,代表数据中共有n个待解决的游戏初始状态。 以下若干行数据分为n组,每组数据有5行,每行5个字符。每组数据描述了一个游戏的初始状态。各组数据间用一个空行分隔。 对于30%的数据,n<=5; 对于100%的数据,n<=500。
输出格式 输出数据一共有n行,每行有一个小于等于6的整数,它表示对于输入数据中对应的游戏状态最少需要几步才能使所有灯变亮。 对于某一个游戏初始状态,若6步以内无法使所有灯变亮,请输出「-1」。
样例输入 3 00111 01011 10001 11010 11100
11101 11101 11110 11111 11111
01111 11111 11111 11111 11111
样例输出 3 2 -1
程序代码
const
BigPrime=3214567;
MaxStep=6;
type
pointer=^rec;
rec=record
v:longint;
step:integer;
next:pointer;
end;
var
total:longint;
hash:array[0..BigPrime-1]of pointer;
q:array[1..400000]of rec;
function update(a:longint;p:integer):longint;
begin
a:=a xor (1 shl p);
if p mod 5<>0 then a:=a xor (1 shl (p-1));
if (p+1) mod 5<>0 then a:=a xor (1 shl (p+1));
if p<20 then a:=a xor (1 shl (p+5));
if p>4 then a:=a xor (1 shl (p-5));
exit(a);
end;
function find(a:longint;step:integer):boolean;
var
now:pointer;
begin
now:=hash[a mod BigPrime];
while now<>nil do
begin
if now^.v=a then exit(true);
now:=now^.next;
end;
new(now);
now^.v:=a;
now^.step:=step;
now^.next:=hash[a mod BigPrime];
hash[a mod BigPrime]:=now;
total:=total+1;
exit(false);
end;
procedure solve;
var
p:integer;
close:longint=0;
open:longint=1;
begin
find(1 shl 25-1,0);
q[1].v:=1 shl 25-1;
q[1].step:=0;
repeat
inc(close);
for p:=0 to 24 do
if not find(update(q[close].v,p),q[close].step+1) and (q[close].step+1<MaxStep) then
begin
open:=open+1;
q[open].v:=update(q[close].v,p);
q[open].step:=q[close].step+1;
end;
until close>=open;
end;
procedure print(a:longint);
var
now:pointer;
begin
now:=hash[a mod BigPrime];
while now<>nil do
begin
if now^.v=a then
begin
writeln(now^.step);
exit;
end;
now:=now^.next;
end;
writeln(-1);
end;
procedure main;
var
ch:char;
i,j,n:integer;
t:longint;
begin
readln(n);
for i:=1 to n do
begin
t:=0;
for j:=1 to 25 do
begin
read(ch);
t:=t*2+ord(ch)-48;
if j mod 5=0 then readln;
end;
print(t);
if i<n then readln;
end;
end;
begin
solve;
main;
end.
Problem : garden / 和MM逛花园
题目来源
问题描述
花园设计强调,简单就是美。Matrix67常去的花园有着非常简单的布局:花园的所有景点的位置都是「对齐」了的,这些景点可以看作是平面坐标上的格点。相邻的景点之间有小路相连,这些小路全部平行于坐标轴。景点和小路组成了一个「不完整的网格」。
一个典型的花园布局如左图所示。花园布局在6行4列的网格上,花园的16个景点的位置用红色标注在了图中。黑色线条表示景点间的小路,其余灰色部分实际并不存在。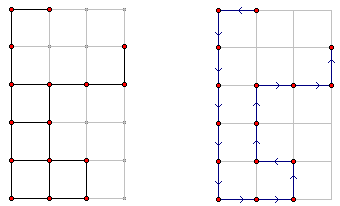
Matrix67 的生日那天,他要带着他的MM在花园里游玩。Matrix67不会带MM两次经过同一个景点,因此每个景点最多被游览一次。
他和他的MM边走边聊,他们是 如此的投入以致于他们从不会「主动地拐弯」。也就是说,除非前方已没有景点或是前方的景点已经访问过,否则他们会一直往前走下去。当前方景点不存在或已游 览过时,Matrix67会带MM另选一个方向继续前进。由于景点个数有限,访问过的景点将越来越多,迟早会出现不能再走的情况(即四个方向上的相邻景点 都访问过了),此时他们将结束花园的游览。Matrix67希望知道以这种方式游览花园是否有可能遍历所有的景点。Matrix67可以选择从任意一个景 点开始游览,以任意一个景点结束。
在上图所示的花园布局中,一种可能的游览方式如右图所示。这种浏览方式从(1,2)出发,以(2,4)结束,经过每个景点恰好一次。
输入格式
第一行输入两个用空格隔开的正整数m和n,表示花园被布局在m行n列的网格上。
以下m行每行n个字符,字符「0」表示该位置没有景点,字符「1」表示对应位置有景点。这些数字之间没有空格。
输出格式
你的程序需要寻找满足「不主动拐弯」性质且遍历所有景点的游览路线。
如果没有这样的游览路线,请输出一行「Impossible」(不带引号,注意大小写)。
如果存在游览路线,请依次输出你的方案中访问的景点的坐标,每行输出一个。坐标的表示格式为「(x,y)」,代表第x行第y列。
如果有多种方案,你只需要输出其中一种即可。评测系统可以判断你的方案的正确性。
样例输入
6 4 1100 1001 1111 1100 1110 1110
样例输出
(1,2) (1,1) (2,1) (3,1) (4,1) (5,1) (6,1) (6,2) (6,3) (5,3) (5,2) (4,2) (3,2) (3,3) (3,4) (2,4)
数据规模
对于30%的数据,n,m<=5; 对于100%的数据,n,m<=10。
程序代码:
program garden;
const
dir:array[1..4,1..2]of integer=
((1,0),(0,1),(-1,0),(0,-1));
type
arr=array[1..10]of integer;
rec=record x,y:integer;end;
var
map:array[0..11,0..11]of boolean;
ans:array[1..100]of rec;
n,m,max:integer;
step:integer=1;
state:arr;
procedure readp;
var
i,j:integer;
ch:char;
begin
readln(m,n);
for i:=1 to n do
begin
for j:=1 to m do
begin
read(ch);
map[i,j]:=(ch='1');
inc(max,ord( map[i,j] ))
end;
readln;
end;
end;
procedure writep;
var
i:integer;
begin
for i:=1 to step do
writeln( '(' , ans[i].x , ',' , ans[i].y , ')' );
end;
procedure solve(x,y:integer);
var
tx,ty,d:integer;
step\_cache:integer;
state\_cache:arr;
begin
step\_cache:=step;
state\_cache:=state;
if step=max then
begin
writep;
exit;
end;
for d:=1 to 4 do
begin
tx:=x+dir[d,1];
ty:=y+dir[d,2];
while map[tx,ty] and ( not state[tx] and(1 shl (ty-1) )>0) do
begin
inc(step);
ans[step].x:=tx;
ans[step].y:=ty;
state[tx]:=state[tx] or ( 1 shl (ty-1) );
tx:=tx+dir[d,1];
ty:=ty+dir[d,2];
end;
tx:=tx-dir[d,1];
ty:=ty-dir[d,2];
if (tx<>x) or (ty<>y) then solve(tx,ty);
state:=state\_cache;
step:=step\_cache;
end;
end;
{====main====}
var
i,j:integer;
begin
assign(input,'garden.in');
reset(input);
assign(output,'garden.out');
rewrite(output);
readp;
for i:=1 to n do
for j:=1 to m do
if map[i,j] then
begin
ans[1].x:=i;
ans[1].y:=j;
state[i]:=1 shl (j-1);
solve(i,j);
state[i]:=0;
end;
close(input);
close(output);
end.
Problem : cowfood / 玉米地
题目来源
USACO月赛
问题描述
农夫约翰购买了一处肥沃的矩形牧场,分成M*N(1<=M<=12; 1<=N<=12)个格子。他想在那里的一些格子中种植美味的玉米。遗憾的是,有些格子区域的土地是贫瘠的,不能耕种。 精明的约翰知道奶牛们进食时不喜欢和别的牛相邻,所以一旦在一个格子中种植玉米,那么他就不会在相邻的格子中种植,即没有两个被选中的格子拥有公共边。他还没有最终确定哪些格子要选择种植玉米。 作为一个思想开明的人,农夫约翰希望考虑所有可行的选择格子种植方案。由于太开明,他还考虑一个格子都不选择的种植方案!请帮助农夫约翰确定种植方案总数。
输入格式:
第一行:两个用空格分隔的整数M和N 第二行到第M+1行:第i+1行描述牧场第i行每个格子的情况,N个用空格分隔的整数,表示这个格子是否可以种植(1表示肥沃的、适合种植,0表示贫瘠的、不可种植)
输出格式
一个整数,农夫约翰可选择的方案总数除以 100,000,000 的余数
样例输入
2 3 1 1 1 0 1 0
样例输出
9
样例说明
给可以种植玉米的格子编号: 1 2 3 4
只种一个格子的方案有四种(1,2,3或4),种植两个格子的方案有三种(13,14或34),种植三个格子的方案有一种(134),还有一种什么格子都不种。 4+3+1+1=9。
数据规模
对于30%的数据,N,M<=4; 对于100%的数据,N,M<=12。
程序代码:
program cowfood;
const
d=100000000;
MaxN=12;
var
f:array[0..MaxN,1..2000]of longint;
w:array[1..2000,1..2000]of boolean;
st:array[0..2000]of integer;
map:array[0..MaxN]of integer;
m,n:integer;
function Impossible(a:integer):boolean;
var
i:integer;
flag:boolean=false;
begin
for i:=1 to MaxN do
begin
if flag and (a and 1=1) then exit(true);
flag:=(a and 1=1);
a:=a shr 1;
end;
exit(false);
end;
function Conflict(a,b:integer):boolean;
var
i:integer;
begin
for i:=1 to MaxN do
begin
if (a and 1=1) and (b and 1=1) then exit(true);
a:=a shr 1;
b:=b shr 1;
end;
exit(false);
end;
function CanPlace(a,b:integer):boolean;
begin
exit(a or b=b);
end;
procedure FindSt;
var
i:integer;
begin
for i:=0 to 1 shl MaxN-1 do
if not Impossible(i) then
begin
inc(st[0]);
st[st[0]]:=i;
end;
end;
procedure Init;
var
i,j:integer;
begin
for i:=1 to st[0] do
for j:=i to st[0] do
if not Conflict(st[i],st[j]) then
begin
w[i,j]:=true;
w[j,i]:=true;
end;
end;
procedure Readp;
var
i,j,t,v:integer;
begin
readln(m,n);
for i:=1 to m do
begin
v:=0;
for j:=1 to n do
begin
read(t);
v:=v*2+t;
end;
map[i]:=v;
readln;
end;
end;
procedure Solve;
var
i,j,k:integer;
begin
f[0,1]:=1;
map[0]:=1 shl n-1;
for i:=1 to m do
for j:=1 to st[0] do
if not CanPlace(st[j],map[i]) then f[i,j]:=-1 else
for k:=1 to st[0] do if (f[i-1,k]<>-1) and w[j,k] then
f[i,j]:=(f[i,j]+f[i-1,k]) mod d;
end;
procedure Writep;
var
j:integer;
ans:longint=0;
begin
for j:=1 to st[0] do
if f[m,j]<>-1 then ans:=(ans+f[m,j]) mod d;
writeln(ans);
end;
begin
assign(input,'cowfood.in');
reset(input);
assign(output,'cowfood.out');
rewrite(output);
FindSt;
Init;
Readp;
Solve;
Writep;
close(input);
close(output);
end.
Ceeji的总结
二进制和位运算高深莫测,没有 Matrix67 那样牛的人不必要全部掌握,能会前面的内容就很不错了。比如我。
© 转载需附带本文链接,依据 CC BY-NC-SA 4.0 发布。